In the code: defeating the unknown
07.11.2018 – Reto Ischi
Article for inside-it.ch, 7 November 2018
Why protect an insecure web application with an additional security product such as a web application firewall (WAF)? Wouldn’t it make more sense to invest these resources in developing secure applications or in identifying and eliminating vulnerabilities? I am often asked this question when talking to application developers. With the way that today’s web applications are developed, configured and deployed, it is unfortunately virtually impossible to eradicate all security flaws. Even if the program code you have written yourself meets the applicable quality standards, it may depend on other components that do not.
So how exactly can the security of a web application be guaranteed? For the answer, we turn to the wisdom of fort builders from the middle ages: defence in depth. By combining multiple independent security systems, it is possible to reduce the risk of a successful attack. In a system like this, a WAF plays a key role in protecting the web application.
Airlock and machine learning
Machine learning (ML) has exploded in popularity in recent years, and the use of associated technologies is increasingly finding its way into the field of IT security. At Ergon Informatik too, a team of machine learning and web security specialists is currently investigating the use of ML methods in connection with the Airlock web application firewall. This article provides an overview of the opportunities and risks associated with using ML-based methods with WAFs.
The main task of a WAF is to protect downstream web applications against technical attacks. Here, ML can be used for much more than just detecting web attacks. It can also be used for log analysis, or to support administrators in creating or optimising complex WAF configurations.
Traditional methods and machine learning – a complementary pairing
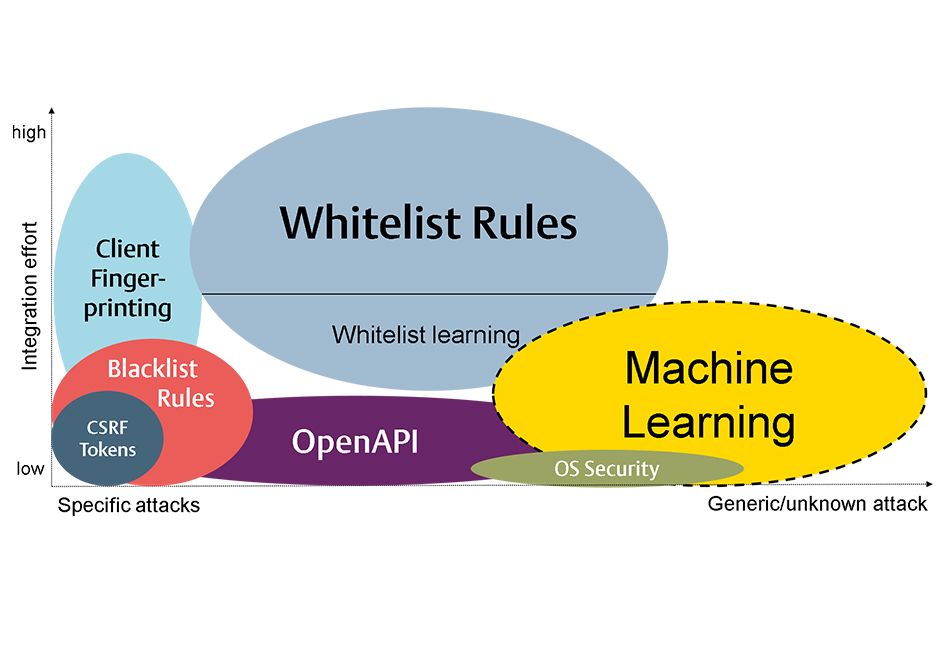
Most security risks in web applications can be prevented, or at least significantly reduced, by a specific WAF function. Rule-based systems are usually used for this. In the case of older web applications, most of the application logic is located on the server, with the client following the specified procedure, for example allowing a user to fill in a presented form. Systems like these can be protected very effectively using dynamic rules such as URL encryption, HTML signing, form elements or CSRF tokens. In contrast, modern web applications, where the majority of the application logic is executed by the client, can be much more difficult to safeguard using dynamic functions.
A drawback of rule-based systems is that they usually only protect against a very specific attack vector, or take a great deal of effort to integrate. ML-based methods can offer added value here, as they can be used even when the attack vector is not specifically known. The diagram below rates a selection of typical WAF security functions in terms of their integration complexity and their ability to detect unknown attacks. As the diagram shows, no single security feature covers the entire horizontal axis, in other words all possible attack vectors. Specific attacks, such as cross-site request forgery or known code injection attacks, continue to be most effectively prevented through highly specific security functions that are tailored to these attack vectors.
The right aggregation level
WAFs typically make decisions based on individual requests or a group of requests, for instance all requests within an HTTP session or from the same source IP address. If we look at a group of requests within an HTTP session, interesting properties can be defined and statistically evaluated. For example, the likelihood of a specific sequence of HTTP requests within a session can be examined. Typical sequences are usually dominated by normal user behaviour. Atypical sequences may indicate unwanted activities, such as a web crawler which calls up links in an unusual order. One of the difficulties within the session scope is triggering counter-measures, such as blocking the session, early enough when an attack occurs. Another problem lies in the fact that attackers may spread their attacks across several sessions. This is especially easy to do with publicly accessible web applications.
Machine learning needs engineering too
In order to detect an unwanted HTTP session using ML-based methods, appropriate features must first be defined (feature engineering). Here, the underlying data is used to identify attributes for which the model subsequently makes predictions. This step is essential to the success of the model. Examples of such features in web traffic include distributions of the time intervals of requests, HTTP object sizes, or the distribution of HTTP status codes. As can be seen in these examples, individual basic attributes in the raw data, such as time stamps, can be used to construct more complex features in several steps. On the basis of these features, suitable ML models are then selected, configured and trained. A suitable combination of different models gives rise to a system that is able to identify certain abnormalities in a web session. This system can answer questions such as: were individual requests in the session executed by a person, or was this done by software alone? Is this a normal user, or does their behaviour suggest that they are a hacker? If the requests were triggered by a piece of software, was this a legitimate search engine, a monitoring tool, or possible an unwanted site crawler, bot or even attack tool?
In this context, each web application can be trained and protected with its own dedicated model. A specific anomaly in one application, for instance, may be completely normal behaviour in another. This offers a further benefit over static security functions, which take a great deal of effort to configure and optimise for each individual web application. When training the models, steps must also be taken to ensure that the attacker cannot influence the training phase, and that the models can handle this sort of unwanted data.
No room for black-and-white thinking
In contrast to traditional rule-based systems, ML models do not provide black-and-white answers. Instead, they deal in probability distributions. Actions can then be initiated on the basis of these distributions. Terminating a session or temporarily blocking a source IP are generally only desirable solutions if there is a high probability of an attack. Meanwhile, other actions such as displaying a CAPTCHA should only be executed if requests have been triggered that are highly likely to have been automated, for example by a bot. If the level of uncertainty is too high, session details can also simply be logged or sent to a peripheral system, such as a fraud detection system, which then conducts initial analysis and makes decisions.
Safety of ML-based systems
As ML models are used nowadays in highly critical systems such as self-driving cars, where the wrong decision could have fatal consequences, the robustness of such models has increasingly come under scrutiny in recent years. Even if road signs, for example, can easily be detected with a high level of certainty, it has been found that less robust models can be tricked. An attacker can make barely perceptible changes to a stop sign on the road, which results in the system classifying it as a 70 mph speed limit sign instead.
In many projects, the issue of whether an ML model is sufficiently robust has gone unaddressed. It is clear that this factor is highly relevant when considering the safety of such models. A relatively simple way of making models more resilient to attacks like these is to train them with examples of such attacks, using what is known as perturbed training data.
Summary
The potential for using ML models in security products such as WAFs is huge. However, statistical approaches to problem-solving also carry a wealth of new risks. The trick here is to identify the areas in which such systems can actually provide added value, as well as determining the details of how they need to be designed in order to meet the requirements concerning security – and in particular operability. Sound expertise in application security and machine learning are essential to ensuring the success of projects like these.
Reto Ischi is Head of Research and Development for Airlock WAF at Zurich-based software manufacturer Ergon, and has worked in the field of information security and software development for more than 17 years. His responsibilities include designing and developing new security features. Reto Ischi completed a master’s degree in information security at ETH Zurich. He is currently undertaking further study at ETH Zurich in the field of data science.